JVM java代码运行 基本类型
除了 Java 外,Scala、Clojure、Groovy,以及时下热门的 Kotlin,这些语言都可以运行在 Java 虚拟机之上。
Java代码是如何运行的
Java 代码有很多种不同的运行方式。比如说可以在开发工具中运行,可以双击执行 jar 文件运行,也可以在命令行中运行,甚至可以在网页中运行。当然,这些执行方式都离不开 JRE,也就是 Java 运行时环境。
JRE 仅包含运行 Java 程序的必需组件,包括 Java 虚拟机以及 Java 核心类库等。JDK(Java 开发工具包)同样包含了 JRE,并且还附带了一系列开发、诊断工具。
运行 C++ 代码则无需额外的运行时。往往把这些代码直接编译成 CPU 所能理解的代码格式,也就是机器码。
为什么Java要在虚拟机中运行
当前的主流思路是这样子的,设计一个面向 Java 语言特性的虚拟机,并通过编译器将 Java 程序转换成该虚拟机所能识别的指令序列,也称 Java 字节码。之所以这么取名,是因为 Java 字节码指令的操作码(opcode)被固定为一个字节。
Java 虚拟机可以由硬件实现 ,但更为常见的是在各个现有平台(如 Windows_x64、Linux_aarch64)上提供软件实现。这么做的意义在于,一旦一个程序被转换成 Java 字节码,那么便可以在不同平台上的虚拟机实现里运行。也就是经常说的“一次编写,到处运行”。
虚拟机的另外一个好处是托管环境(Managed Runtime)。这个托管环境能够代替处理一些代码中冗长而且容易出错的部分。其中最广为人知的当属自动内存管理与垃圾回收。除此之外,托管环境还提供了诸如数组越界、动态类型、安全权限等等的动态检测,免于书写无关业务逻辑的代码。
Java虚拟机运行java字节码
以标准 JDK 中的 HotSpot 虚拟机为例,从虚拟机视角来看,执行 Java 代码首先需要将编译而成的 class 文件加载到 Java 虚拟机中。加载后的 Java 类会被存放于方法区(Method Area)中。实际运行时,虚拟机会执行方法区内的代码。
与X86中段式内存管理代码段类似。java虚拟机同样在内存中划分出堆和栈来存储运行时数据。并且Java虚拟机会将栈细分为面向 Java 方法的 Java 方法栈,面向本地方法(用 C++ 写的 native 方法)的本地方法栈,以及存放各个线程执行位置的 PC 寄存器。
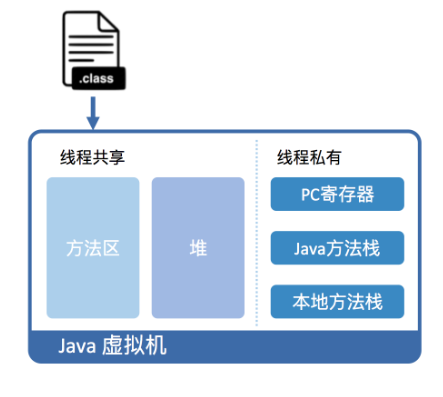
在运行过程中,每当调用进入一个 Java 方法,Java 虚拟机会在当前线程的 Java 方法栈中生成一个栈帧,用以存放局部变量以及字节码的操作数。这个栈帧的大小是提前计算好的,而且 Java 虚拟机不要求栈帧在内存空间里连续分布。当退出当前执行的方法时,不管是正常返回还是异常返回,Java 虚拟机均会弹出当前线程的当前栈帧,并将之舍弃。
从硬件视角来看,Java 字节码无法直接执行。因此,Java 虚拟机需要将字节码翻译成机器码。在 HotSpot 里面,翻译过程有两种形式:第一种是解释执行,即逐条将字节码翻译成机器码并执行;第二种是即时编译(Just-In-Time compilation,JIT),即将一个方法中包含的所有字节码编译成机器码后再执行。
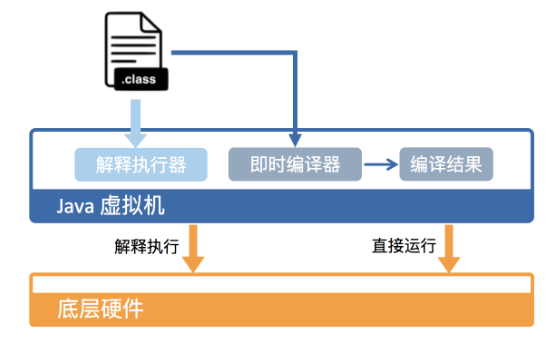
前者的优势在于无需等待编译,而后者的优势在于实际运行速度更快。HotSpot 默认采用混合模式,综合了解释执行和即时编译两者的优点。它会先解释执行字节码,而后将其中反复执行的热点代码,以方法为单位进行即时编译。
JVM运行效率
HotSpot 采用了多种技术来提升启动性能以及峰值性能,即时编译便是其中最重要的技术之一。
即时编译建立在程序符合二八定律的假设上,也就是百分之二十的代码占据了百分之八十的计算资源。对于占据大部分的不常用的代码,无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,则可以将其编译成机器码,以达到理想的运行速度。
理论上讲,即时编译后的 Java 程序的执行效率,是可能超过 C++ 程序的。这是因为与静态编译相比,即时编译拥有程序的运行时信息,并且能够根据这个信息做出相应的优化。例如,虚方法是用来实现面向对象语言多态性的。对于一个虚方法调用,尽管有很多个目标方法,但在实际运行过程中可能只调用其中的一个。这个信息便可以被即时编译器所利用,来规避虚方法调用的开销,从而达到比静态编译的 C++ 程序更高的性能。
即时编译器
为了满足不同用户场景的需要,HotSpot 内置了多个即时编译器:C1、C2 和 Graal。Graal 是 Java 10 正式引入的实验性即时编译器。之所以引入多个即时编译器,是为了在编译时间和生成代码的执行效率之间进行取舍。
- C1 又叫做 Client 编译器,面向的是对启动性能有要求的客户端 GUI 程序,采用的优化手段相对简单,因此编译时间较短。
- C2 又叫做 Server 编译器,面向的是对峰值性能有要求的服务器端程序,采用的优化手段相对复杂,因此编译时间较长,但同时生成代码的执行效率较高。
- 从 Java 7 开始,HotSpot 默认采用分层编译的方式:热点方法首先会被 C1 编译,而后热点方法中的热点会进一步被 C2 编译。
为了不干扰应用的正常运行,HotSpot 的即时编译是放在额外的编译线程中进行的。HotSpot 会根据 CPU 的数量设置编译线程的数目,并且按 1:2 的比例配置给 C1 及 C2 编译器。在计算资源充足的情况下,字节码的解释执行和即时编译可同时进行。编译完成后的机器码会在下次调用该方法时启用,以替换原本的解释执行。
对于发布频率不频繁(也就是长时间运行)的程序,其实选择线下编译和即时编译都一样,因为至多一两个小时后该即时编译的都已经编译完成了。另外,即时编译器因为有程序的运行时信息,优化效果更好,也就是说峰值性能更好。
Java基本类型
Java 引进了八个基本类型,来支持数值计算。Java 这么做的原因主要是工程上的考虑,因为使用基本类型能够在执行效率以及内存使用两方面提升软件性能。
JVM的boolean类型
在 Java 虚拟机规范中,boolean 类型则被映射成 int 类型。具体来说,“true”被映射为整数 1,而“false”被映射为整数 0。这个编码规则约束了 Java 字节码的具体实现。
对于 Java 虚拟机来说,它看到的 boolean 类型,早已被映射为整数类型。因此,将原本声明为 boolean 类型的局部变量,(改动字节码)赋值为除了 0、1 之外的整数值,在 Java 虚拟机看来是“合法”的。
Java的基本类型
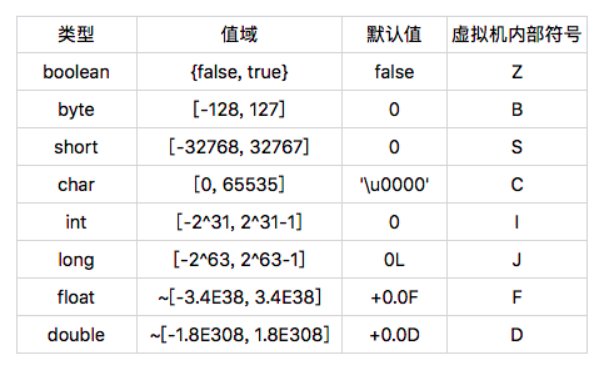
前面的值域被后面的值域所包含,因此,从前面的基本类型转换至后面的基本类型,无需强制转换。尽管他们的默认值看起来不一样,但在内存中都是 0。
基本类型中,boolean 和 char 是唯二的无符号类型。通常可以认定 char 类型的值为非负数。这种特性十分有用,比如说作为数组索引等。
Java 的浮点类型采用 IEEE 754 浮点数格式。以 float 为例,浮点类型通常有两个 0,+0.0F 以及 -0.0F。前者在 Java 里是 0,后者是符号位为 1、其他位均为 0 的浮点数,在内存中等同于十六进制整数 0x8000000(即 -0.0F 可通过 Float.intBitsToFloat(0x8000000) 求得)。尽管它们的内存数值不同,但是在 Java 中 +0.0F == -0.0F 会返回真。有了 +0.0F 和 -0.0F 这两个定义后,便可以定义浮点数中的正无穷及负无穷。正无穷就是任意正浮点数(不包括 +0.0F)除以 +0.0F 得到的值,而负无穷是任意正浮点数除以 -0.0F 得到的值。在 Java 中,正无穷和负无穷是有确切的值,在内存中分别等同于十六进制整数 0x7F800000 和 0xFF800000。 0x7F800001 又对应 NaN(Not-a-Number)。不仅如此,[0x7F800001, 0x7FFFFFFF] 和 [0xFF800001, 0xFFFFFFFF] 对应的都是 NaN。通过 +0.0F/+0.0F,在内存中应为 0x7FC00000。这个数值,我们称之为标准的 NaN,而其他的我们称之为不标准的 NaN。
NaN 有一个有趣的特性:除了“!=”始终返回 true 之外,所有其他比较结果都会返回 false。举例来说,“NaN<1.0F”返回 false,而“NaN>=1.0F”同样返回 false。对于任意浮点数 f,不管它是 0 还是 NaN,“f!=NaN”始终会返回 true,而“f==NaN”始终会返回 false。在程序里做浮点数比较的时候,需要考虑上述特性。
Java基本类型的大小
Java 虚拟机每调用一个 Java 方法,便会创建一个栈帧。其中解释器用的解释栈帧有两个主要的组成部分,分别是局部变量区,以及字节码的操作数栈。这里的局部变量是广义的,除了普遍意义下的局部变量之外,它还包含实例方法的“this 指针”以及方法所接收的参数。
在 Java 虚拟机规范中,局部变量区等价于一个数组,并且可以用正整数来索引。除了 long、double 值需要用两个数组单元来存储之外,其他基本类型以及引用类型的值均占用一个数组单元。
即boolean、byte、char、short 这四种类型,在栈上占用的空间和 int 是一样的,和引用类型也是一样的。因此,在 32 位的 HotSpot 中,这些类型在栈上将占用 4 个字节;而在 64 位的 HotSpot 中,他们将占 8 个字节。
这种情况仅存在于局部变量,而并不会出现在存储于堆中的字段或者数组元素上。对于 byte、char 以及 short 这三种类型的字段或者数组单元,它们在堆上占用的空间分别为一字节、两字节,以及两字节,也就是说,跟这些类型的值域相吻合。
Java 虚拟机的算数运算几乎全部依赖于操作数栈。也就是说,需要将堆中的 boolean、byte、char 以及 short 加载到操作数栈上,而后将栈上的值当成 int 类型来运算。